Are you tired of hearing the buzzword “machine learning” thrown around without really understanding what it means? Well, fear not! In this blog post, we’re going to demystify the world of machine learning and introduce you to some key concepts that will have you feeling like a data scientist in no time. So put on your thinking cap and get ready to expand your knowledge because we’re about to dive into the exciting world of machine learning!
Introduction
Machine learning is the technology that’s powering some of the most exciting and transformative innovations of our time, from self-driving cars to intelligent virtual assistants. But what is it, exactly? At its core, machine learning is the art of getting computers to learn from data and make decisions or predictions based on what they’ve learned.
Machine learning is allowing us to solve problems that were once thought to be near impossible. Instead of trying to explicitly program a computer to do a complex task, we can instead teach machines to recognize patterns in data. By doing this we can e.g. predict which customers are most likely to buy a product, diagnose diseases more accurately, recognize what is in an image, and even detect fraud before it happens. It’s also helping us to automate tasks that were once thought to be too complex for machines to handle, freeing up humans to focus on more creative and strategic work.
Why should you learn about Machine learning?
Machine learning is more than just a buzzword – it’s a game-changer. This technology is revolutionizing the way we live, work, and interact with the world around us. Here are just a few reasons why machine learning is so important:
1. It’s changing the way we think!
By approaching challenges with a machine learning mindset, we’re able to see new possibilities and create new solutions that would have been impossible just a few years ago.
2. It’s helping us to solve important problems!
From predicting and preventing disease outbreaks to combating climate change, machine learning is providing us with the tools we need to tackle complex issues with greater accuracy and efficiency.
3. It’s increasing our efficiency!
Machine learning isn’t just about solving big-picture problems – it’s also making our day-to-day lives easier and more convenient. Thanks to machine learning-powered applications like virtual assistants and personalized recommendations, we can spend less time on menial tasks and more time doing the things we love.
4. It can drive economic growth!
By automating tasks that were once performed by humans, we’re able to increase efficiency and productivity in industries ranging from manufacturing to finance. This not only creates new job opportunities in the field of machine learning itself, but also in industries that benefit from the increased efficiency and innovation.

Machine learning is a completely new kind of tool, that is being developed all the time! It is becoming more effective and can be used to solve many types of problems. The scope of problems that are being solved with machine learning is increasing day by day!
A brief history of Machine Learning
Machine learning has its roots in the early days of computing, when researchers and computer scientists began exploring ways to create programs that could learn from data. In the 1950s and 1960s, early machine learning algorithms were developed for tasks such as pattern recognition and speech recognition.
One particularly significant individual in the early days of machine learning was Frank Rosenblatt, an American psychologist and computer scientist. In 1957, Rosenblatt introduced the concept of the perceptron, a type of artificial neural network that could learn to recognize patterns in data.

The Mark I Perceptron machine developed by Rosenblatt was based on a simple computational model inspired by the structure and function of the human brain. The perceptron consisted of a single layer of interconnected nodes, or neurons, that were capable of receiving input signals and producing output signals based on a set of weights that were adjusted through a process of learning. The Rosenblatt perceptron was basically the grandfather of modern-day deep neural networks, also inspired by the structure and function of the human brain, that dominate the field and applications today.
Rosenblatt’s perceptron algorithm was able to learn to classify patterns of inputs into one of two categories, making it a powerful tool for tasks such as image and speech recognition. However, the perceptron had limitations, as it could only classify linearly separable data, and was unable to solve more complex problems.
Despite these limitations, the Rosenblatt perceptron laid the groundwork for the development of more advanced neural network models and deep learning algorithms that have revolutionized the field of machine learning in recent years.
One of the most significant breakthroughs in machine learning came in the 1980s with the development of backpropagation. It is a revolutionary algorithm that allows for the efficient computation of gradients in neural networks. This technique made it possible for neural networks to learn from examples using optimization algorithms like gradient descent.
In the 1990s and 2000s, researchers continued to refine machine learning algorithms, and new techniques, such as support vector machines, decision trees, and random forests were developed. These techniques allowed machine learning to be applied to a wide range of problems, from image recognition and natural language processing to fraud detection and recommendation systems.
More recently, deep learning has taken center stage in machine learning research and applications, fueled by the availability of large datasets and powerful computing resources. Deep learning has enabled breakthroughs in areas such as computer vision, speech recognition, and natural language processing.
Overall, machine learning has evolved significantly over the past several decades, and continues to evolve day by day. This evolution is driven by advances in computing power, data availability, and algorithmic innovation. As the field continues to evolve, machine learning is likely to play an increasingly important role in a wide range of industries and applications.
Key Concepts
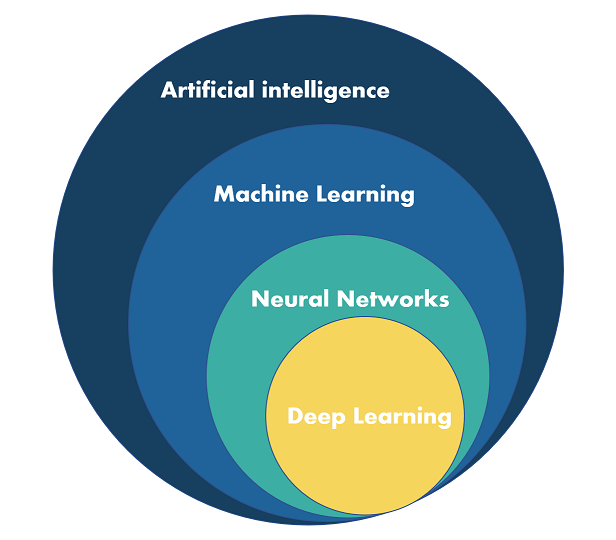
The field of machine learning can roughly be divided into Supervised Learning, Unsupervised Learning, and Reinforcement Learning. I will introduce these concepts next. Additionally, Deep Learning deserves its own introduction as well, although it isn’t really separate from the previous ones, and instead can be used in all of them.
Supervised Learning
Supervised learning is a machine learning approach where the algorithm is trained on a labeled dataset, meaning that each data point is associated with a known output known as a label. The goal of supervised learning is to learn a mapping function from the input variables to the output variables based on the provided labeled data. The algorithm uses this learned mapping function to make predictions on new, unseen data. In other words, in supervised learning, the machine learning model is supervised or guided by the known labeled data during training, and its task is to generalize and make accurate predictions on new, unseen data.
Supervised machine learning can be further divided into three components, which are:
- The Dataset
- The Machine Learning Model (also more technically known as the hypothesis space, or predictor function space)
- The Loss Function
The Dataset contains many data points that are characterized by some numerical features, that are easy to obtain. If the data points represent people, for example, the features could include things such as age, gender, weight, height, etc. Data points are also associated with labels, which are some interesting quantities that we would like to predict from the features, which are also hard to obtain (compared to the features). In the previous example, the label could be e.g. the probability of the person the datapoint represents buying some product.
The Machine learning model (or hypothesis space) refers to the set of all possible candidate mappings that could be learned during the training process. It is the space of all possible functions that the training algorithm can consider when trying to find the best mapping from the features to labels for a given problem. Examples of machine learning models include linear predictor functions, support vector machines, decision trees, and neural networks. The goal of machine learning is to find the best mapping within the hypothesis space that fits the data and generalizes well to new, unseen data.
The loss function is a mathematical function that measures the difference between the predicted output of a model and the correct output. The loss function is used as a guide for the model during training to adjust its parameters in a way that minimizes the difference between the predicted and correct output. The choice of loss function depends on the specific task and the type of model being trained. For example, for classification tasks, cross-entropy loss is commonly used, while for regression tasks, mean squared error is often used. The performance of a model is evaluated based on the value of the loss function on a validation set, and the goal is to find the model with the lowest loss. The loss function is a crucial component of any machine learning algorithm and plays a significant role in determining the accuracy and effectiveness of the trained model.
The process of supervised learning typically involves three main steps: data preparation, model training, and model evaluation. In the data preparation step, the labeled dataset is split into two sets: the training set and the testing set. The training set is used to train the algorithm, while the testing set is used to evaluate the performance of the trained model.
During the model training step, the algorithm uses the labeled training data to learn the mapping function between the input variables and the output variables. This is done by minimizing the loss function.
In the model evaluation step, the trained model is tested on the unseen testing data to assess its performance. Various metrics can be used to evaluate the model’s performance, such as accuracy, precision, recall, and F1 score.

Supervised learning has a wide range of applications, including image classification, speech recognition, natural language processing, and predictive modeling.
Unsupervised Learning
Unsupervised learning is a machine learning technique where the algorithm learns patterns and relationships in a dataset without being explicitly provided with labeled training data. In other words, the algorithm has to discover the underlying structure of the data by itself.
Unlike supervised learning, unsupervised learning does not have a clear objective function or a target variable to optimize. Instead, it aims to identify patterns and relationships within the data by exploring the data’s structure and distribution. Unsupervised learning is commonly used for tasks such as clustering, dimensionality reduction, and anomaly detection.
Here are some examples of unsupervised learning techniques and how they can be used:
- Clustering: Clustering is a common unsupervised learning technique used to group similar data points together. For example, clustering can be used to segment customers based on their purchasing behavior, identify groups of similar images, or group similar genes based on gene expression data.
- Dimensionality reduction: Unsupervised learning techniques such as principal component analysis (PCA) can be used to reduce the dimensionality of high-dimensional data. This can be useful for visualizing high-dimensional data or for speeding up machine learning algorithms by reducing the number of features.
- Anomaly detection: Unsupervised learning techniques such as density-based anomaly detection can be used to identify outliers or anomalies in the data. For example, anomaly detection can be used to detect credit card fraud by identifying unusual patterns in credit card transactions.
- Generative models: Unsupervised learning can be used to train generative models, which can learn to generate new data samples that are similar to the training data. This can be useful for tasks such as image synthesis or language generation.

In summary, unsupervised learning is a powerful technique that can be used to explore and discover patterns and relationships in data without being explicitly provided with labeled training data.
Reinforcement Learning
Reinforcement learning is a machine learning technique where an agent learns to take actions in an environment in order to maximize a reward signal. The agent interacts with the environment by taking actions and receiving feedback in the form of rewards or penalties. The goal of the agent is to learn a policy that maps states to actions in order to maximize the cumulative reward over time.
Here is a brief overview of how reinforcement learning works:
- The agent observes the state of the environment.
- Based on the current state, the agent selects an action to take.
- The environment transitions to a new state and the agent receives a reward or penalty based on the action taken.
- The agent updates its policy based on the observed reward and the new state of the environment.
- The process repeats, with the agent continually updating its policy based on new experiences.
Reinforcement learning can be used in a variety of applications, including robotics, game-playing, and self-driving cars. Here are some examples of how reinforcement learning can be used:
- Game playing: Reinforcement learning has been used to train agents to play games such as Go, Chess, and Atari games. The agent learns to take actions that maximize its chances of winning the game, based on feedback in the form of game scores.
- Robotics: Reinforcement learning can be used to train robots to perform tasks such as grasping objects or navigating through space. The robot learns to take actions that maximize its chances of completing the task, based on feedback in the form of task completion scores.
- Finance: Reinforcement learning can be used to optimize investment strategies. The agent learns to make investment decisions that maximize its return on investment, based on feedback in the form of profits or losses.
- Autonomous vehicles: Reinforcement learning can be used to train autonomous vehicles to navigate through complex environments. The agent learns to take actions that maximize its chances of safely reaching its destination, based on feedback in the form of successful navigation scores.

In summary, reinforcement learning is a machine learning technique where an agent learns to take actions in an environment in order to maximize a reward signal.
Deep Learning
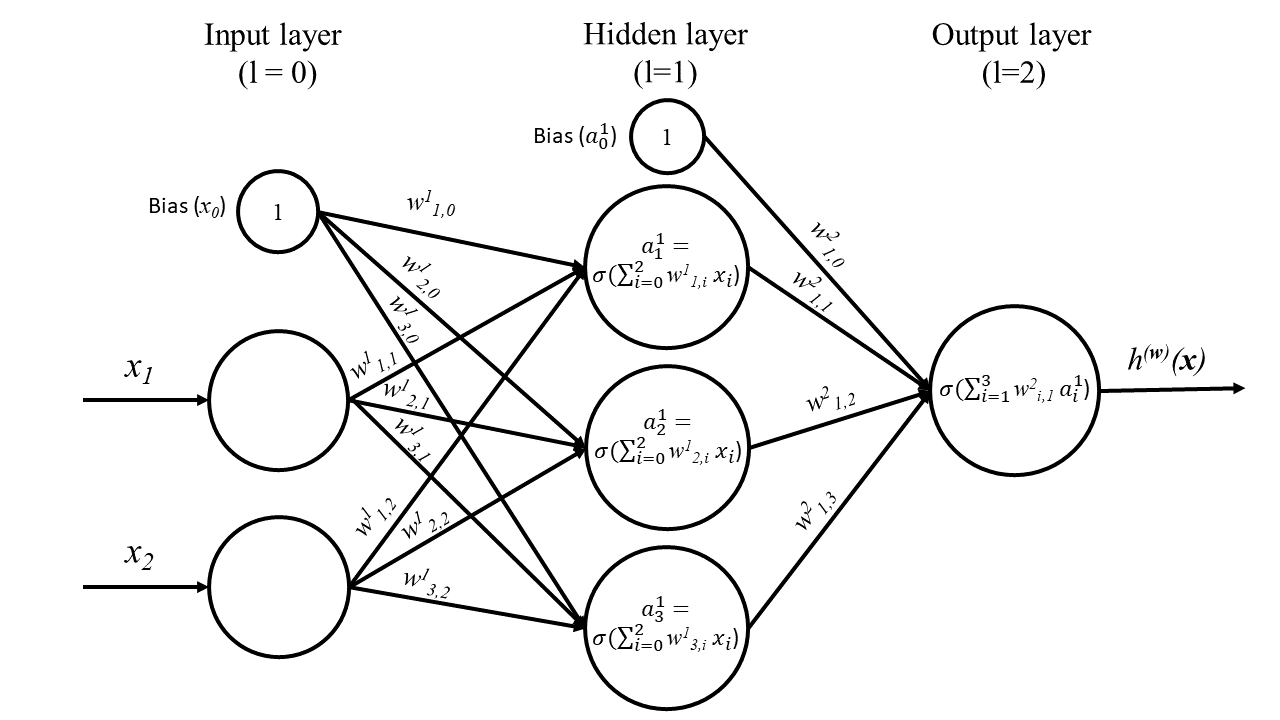
Deep learning is a subfield of machine learning that uses artificial neural networks to learn and make predictions from data. The term “deep” in deep learning refers to the fact that these neural networks are usually composed of many layers, which allows them to learn complex patterns and relationships in data.
At a high level, the basic steps involved in deep learning are as follows:
- Input data is fed into the neural network.
- The neural network processes the data through multiple layers of interconnected nodes, known as neurons.
- Each neuron applies a mathematical function to the input data it receives, and then passes the result on to the next layer of neurons.
- The output of the final layer of neurons is the prediction or classification result.
Here are some examples of how deep learning is used:
- Image recognition: Deep learning can be used to identify objects or people in images. For example, a deep learning model can be trained to recognize cats in photographs by being fed thousands of images of cats and non-cats.
- Natural language processing: Deep learning can be used to analyze and understand human language. For example, a deep learning model can be trained to recognize speech, translate languages, or summarize text.
- Autonomous vehicles: Deep learning can be used to help autonomous vehicles navigate the environment. For example, a deep learning model can be trained to recognize traffic signs and pedestrians, and to make decisions about when to turn, accelerate, or brake.
- Healthcare: Deep learning can be used to analyze medical data and help doctors make diagnoses. For example, a deep learning model can be trained to recognize patterns in medical images such as X-rays or MRIs, and to identify early signs of diseases like cancer.
Overall, deep learning has a wide range of applications and has the potential to revolutionize many industries.
Incredible state-of-the-art tools that you can use right now!
Recently, many incredible and powerful tools powered by artificial intelligence and machine learning have been popping up. Check them out to unleash your creativity! Some of the best ones include for example:
- ChatGPT: An incredible chatbot, which is powered by a cutting-edge large-language-model. The dialogue format makes it possible for ChatGPT to answer follow-up questions, admit mistakes, and challenge incorrect premises.
- Dall·E 2: A state-of-the-art diffusion model that can create realistic images and art from a description in natural language.
- Stable diffusion: A latent text-to-image diffusion model capable of generating photo-realistic images given any text input, cultivates autonomous freedom to produce incredible imagery, and empowers billions of people to create stunning art within seconds.
- Midjourney: Midjourney is an AI art generator that creates high-quality and detailed images, often indistinguishable from art created by a human artist. You can generate images by sending a simple text prompt, and the tool gives you four output images. Midjourney offers a limited free trial with around 25 queries and several pricing options for full membership.
- Jasper: A top-performing AI writing software that can turn simple text inputs into full-blown text chapters for various writing needs, including blog posts and emails. The tool is easy to use and doesn’t require technical skills or planning. It offers a free trial of 10,000 words and supports multiple languages.
- Jasper Art: An AI image generator that turns text input into unique digital art. The tool allows users to experiment with various art styles, including photorealistic images and cartoon-style photos. It is easy to use and has multiple settings to customize the output. Jasper Art supports multiple languages and offers a support chat for assistance. The pricing starts at $20/month, but there is no free trial available at the moment.
- NightCafe: NightCafe is a popular AI art generator that uses advanced algorithms to create unique and original digital art based on text prompts. The tool is easy to use, with a free trial version available and the option to earn or purchase credits for generating more images. NightCafe also offers options for evolving, enhancing, and sharing the generated art, as well as purchasing print versions. The tool has multiple AI algorithms and advanced settings for control and customization.
Conclusion
In conclusion, machine learning has come a long way since its inception and is becoming an essential tool in many industries. As we move forward, we can expect machine learning to continue to evolve, and new techniques and algorithms will be developed that will unlock even more potential for this technology.
If you’re interested in learning more about machine learning, there are plenty of resources available online. Additionally, there are many incredible tools already available for you to start experimenting with. You can use them to help you work more efficiently, expand your own creativity and build innovative solutions for your own needs.
In short, the possibilities with machine learning are endless, and we encourage you to keep learning and exploring the many ways in which it can benefit your work and life. Whether you’re a student, researcher, entrepreneur, or simply curious, there’s never been a better time to dive into the world of machine learning. We hope this article has provided you with a solid foundation to start your journey and wish you the best of luck in your endeavors!